

Web Scraping en Python con BeautifulSoup
¿Qué es Web Scraping?
El web scraping se define como "extraer datos de sitios web o internet" y es exactamente eso — usar código para leer automáticamente sitios web, buscar algo o ver el código fuente de páginas con el fin de guardar algún tipo de información de ellos.
Esto se usa en todas partes, desde los bots de Google que indexan sitios web, hasta recopilar datos sobre estadísticas deportivas, o guardar precios de acciones en una hoja de Excel — las opciones son realmente ilimitadas. Si hay un sitio, página o término de búsqueda que te interesa y quieres recibir actualizaciones al respecto, entonces este artículo es para ti — veremos cómo usar las requests y BeautifulSoup bibliotecas para recopilar datos de sitios web con Python, y podrás transferir fácilmente las habilidades que aprenderás para extraer datos de cualquier sitio web que te interese sin esfuerzo.
¿Qué herramientas usaremos?
Python es el lenguaje preferido para extraer datos de internet, y el requests y BeautifulSoup las bibliotecas son los paquetes de Python ideales para el trabajo. Con requests, puedes fácilmente hacer scraping de cualquier sitio web, y leer sus datos de varias maneras, desde HTML hasta JSON. Como la mayoría de los sitios web están construidos con HTML y extraeremos todo el HTML de la página, luego usaremos el BeautifulSoup paquete de bs4 para analizar ese HTML y encontrar los datos que estamos buscando dentro de él.
Requisitos
Para poder seguir el proceso, vas a necesitar tener Python, requests, y BeautifulSoup instalado.
-
Python: puedes descargar la última versión de Python desde el sitio web oficial, aunque es muy probable que ya lo tengas instalado.
-
requests: si tienes una versión de Python >= 3.4, tienespipinstalado. Puedes usarpipen la línea de comandos escribiendopython3 -m pip install requestsen cualquier directorio. -
BeautifulSoup: esto viene empaquetado bajobs4, pero puedes instalarlo fácilmente conpython3 -m pip install beautifulsoup4.
Programación
Creo que la mejor manera de aprender programación es practicando y construyendo un proyecto, así que te animo encarecidamente a que me sigas en tu editor de texto favorito (recomiendo Visual Studio Code) mientras aprendemos a usar estas dos bibliotecas a través de ejemplos.
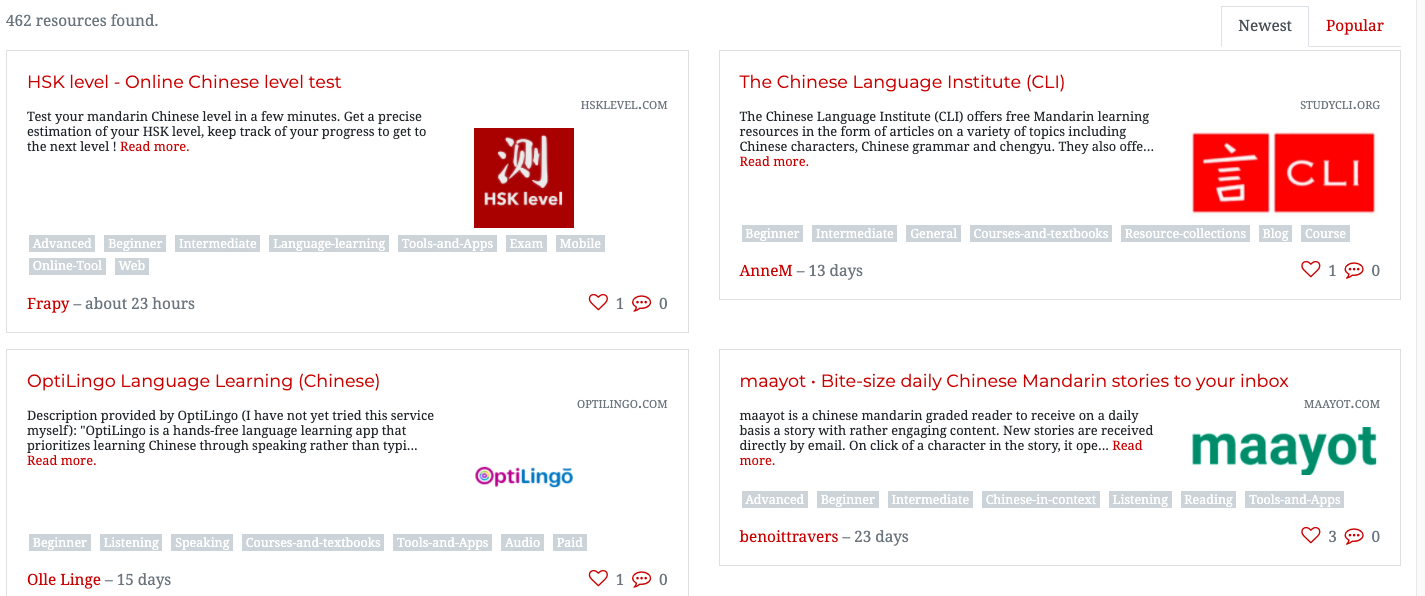
Como estoy aprendiendo mandarín, pensé que sería apropiado crear un scraper que genere una lista de enlaces a recursos de mandarín. Por suerte, investigué previamente y descubrí que hay es un sitio web que almacena listas tipo tarjetas de recursos de mandarín. Sin embargo, estos están distribuidos en casi una docena de páginas, en forma de tarjetas, y muchos de los enlaces están rotos. El sitio web del que extraeremos estos enlaces es un conocido sitio para aprender mandarín, y puedes ver la lista de recursos aquí: https://challenges.hackingchinese.com/resources.
Así que, en este proyecto, extraeremos los enlaces que funcionan de esa lista y los guardaremos en un archivo en nuestra computadora, para poder revisarlos más tarde con tranquilidad sin tener que hacer clic en cada tarjeta del sitio. El programa completo tendrá solo ~40 líneas de código, y trabajaremos en el proyecto en tres pasos individuales.
Analizando el sitio
Antes de comenzar con la programación real, necesitamos ver dónde los datos se están almacenando en el sitio web. Esto se puede hacer mediante la "Inspección" de la página. Puedes inspeccionar una página haciendo clic derecho en cualquier lugar dentro de la página y luego seleccionando "Inspeccionar". Si seleccionas eso, aparecerá el código fuente de la página en la parte inferior de tu pantalla, un montón de HTML de aspecto intimidante. No te preocupes — la BeautifulSoup biblioteca nos facilitará esto.
Vamos a "Inspeccionar" el primer resultado en el sitio web en https://challenges.hackingchinese.com/resources, específicamente HSK level — Online Chinese level test. Para hacerlo, necesitamos colocar nuestro ratón justo encima de lo que queremos extraer — que es el título, ya que también es un enlace — y luego hacer clic en "Inspeccionar", lo que abrirá el código fuente y nos llevará exactamente a donde queremos estar — en el enlace.
Si lo haces, deberías ver algo como lo siguiente:
class="card-title" style="font-size: 1.1rem">
href="http://www.hsklevel.com">HSK level — Online Chinese level test
¡Buenas noticias! Parece que cada enlace está dentro de un encabezado h4. Siempre que extraemos datos de un sitio web, necesitamos buscar el "identificador" único para esos datos. En este caso, es el encabezado h4, ya que no hay otros en el sitio que no estén relacionados con los enlaces. Otra opción podría ser buscar basándose en font-size o el class de card-title, pero optaremos por el encabezado h4 ya que es lo más simple.
Extrayendo los enlaces de recursos
Ahora que hemos descubierto cómo se ve el código fuente del sitio web, necesitamos comenzar a extraer el contenido. Guardaremos cada enlace en un archivo en nuestro dispositivo llamado links.txt, y necesitamos solo unas docenas de líneas para completar el trabajo.
Comencemos.
- Importando Bibliotecas
Necesitamos las bibliotecas mencionadas anteriormente para ejecutar el programa. Crea un nuevo archivo llamadoscrape_links.pyy escribe lo siguiente:
import requests, time desde bs4 import BeautifulSoup - Extrayendo Datos del Sitio
Como el sitio web tiene sus recursos divididos en varias páginas, tiene sentido extraerlos dentro de una función para que podamos repetirla. Llamemos a esta funciónextract_resources, y tendrá un parámetro que define su número de página.
def extract_resources(page: int -> None): # use an f-string to access the correct page page = requests.get(f'https://challenges.hackingchinese.com/resources/stories?page={page}) soup = BeautifulSoup(page.content, 'html.parser')Estamos utilizando la variable
souppara mantener un objetoBeautifulSoupdel sitio web. Lo estamos convirtiendo a HTML conhtml.parsery los datos que estamos convirtiendo son el contenido de la variablepage.links = soup.find_all('h4')Usaremos
BeautifulSouppara encontrar todos los HTML que son encabezados, y los guardaremos en una lista llamadalinkscon sus elementos HTML secundarios (en este caso, el enlace). - Recopilando nuestros Datos
for i en range(len(links)): try: if links[i]['class'] == ['card-title']: true_links.append(links[i]) except: passEn la primera línea, estamos iterando a través de cada encabezado h4 en
links. Comprobamos si su clase escard-title, como vimos en Analizando el sitio, para asegurarnos de evitar cualquier encabezado h4 que no sean tarjetas — solo por si acaso. Si es un h4 relacionado con tarjetas con un enlace, entonces lo agregaremos a la lista previamente vacíatrue_linkscon todos los correcto h4s.
Finalmente, envolveremos esto en untry: except:bucle en caso de que el h4 no tenga caso, para evitar que el programa falle ya queBeautifulSoupno puede manejar la solicitud. - Guardando los Enlaces
# open file with w+ (generate it if it does not exist) file = open("links.txt", "w+") for i en range(len(true_links)): file.write(str(list(true_links[i].children)[0]['href']) + '\n') file.close()En lugar de imprimir la lista, vamos a guardarla para no tener que ejecutar el archivo Python varias veces y tenerlo en un formato más fácil de ver.
Primero, abrimos el archivo, y lo estamos abriendo conw+para que si no existe, podamos generar un archivo en blanco con su nombre.
Segundo, iteramos a través de la lista detrue_links. Para cada elemento, escribimos en el archivo con su enlace usandofile.write(). Cuando estábamos analizando el sitio por primera vez, vimos que el enlace es un elemento hijo del encabezado HTML h4. Así que, usamosBeautifulSouppara acceder al primer hijo detrue_links[i], que necesitamos envolver en una lista ya que de otro modo es un objeto Python.
En este punto, tenemoslist(true_links[i].children)[0]. Sin embargo, lo que estamos buscando es el enlace real del hijo. En lugar deTextqueremos solo el enlace, al que podemos acceder con['href']. Una vez que tenemos esto, necesitamos envolver todo en una cadena para que se genere como una cadena y luego agregar '\n' para asegurar que cada enlace esté en una nueva línea cuandofile.write()lo hagamos.
Por último, realizamosfile.close()para cerrar el archivo que abrimos.
Si ejecutas el programa y esperas unos minutos, deberías encontrar que ahora tienes un archivo llamadolinks.txtcon cientos de enlaces que extrajimos con Python. ¡Felicitaciones! Sin Python, habría tomado mucho más tiempo obtener manualmente cada URL.
Antes de terminar, vamos a ver otra forma en la que podemos usar larequestsbiblioteca comprobando el estado de cada enlace.
Bonus: Eliminando enlaces rotos
El sitio web del que estamos extrayendo información no se mantiene en buenas condiciones, y algunos de los enlaces están desactualizados o completamente muertos. Así que, en este paso opcional, veremos otro aspecto de la extracción que devuelve el código de estado de cada sitio web, y los descarta si es un 404 — lo que significa no encontrado.
Vamos a necesitar modificar ligeramente el código utilizado en el Paso 4 anterior. En lugar de simplemente iterar a través de los enlaces y escribirlos en el archivo, primero vamos a asegurarnos de que no estén rotos.
file = open("links.txt", "w+")
for i en range(len(true_links)):
try:
# ensure it is a working link
response = requests.get(str(list(true_links[i].children)[0]['href']), timeout = 5, allow_redirects = True, stream = True)
if response != 404:
file.write(str(list(true_links[i].children)[0]['href']) + '\n')
except: # Connection Refused
pass
file.close()
Hemos hecho algunos cambios — vamos a repasarlos.
- Creamos un
responsevariable que verifica el código de estado del enlace — esencialmente viendo si todavía está allí. Esto puede hacerse con el útilrequests.get()método. Estamos obteniendo el mismo enlace que estamos tratando de añadir, es decir, la URL del sitio web, y dándole 5 segundos para responder, la oportunidad de redirigir, y permitiéndole enviarnos archivos (que no descargaremos), constream = True. - Comprobamos cuál fue la respuesta, viendo si era un 404 o no. Si no lo era, entonces escribimos el enlace, pero si lo era, entonces no hicimos nada y no escribimos el enlace en el archivo. Esto se hizo a través del condicional
if response != 404. - Por último, envolvimos todo en un bucle try — except. Esto es porque si la página tardaba en cargar, no podía ser accedida, o la conexión era rechazada, entonces normalmente el programa fallaría con una Excepción. Sin embargo, como lo envolvimos en este bucle, nada sucederá en caso de una Excepción y simplemente será pasada por alto.
¡Y eso es todo! Si ejecutas el código (y lo dejas corriendo también, porque para requests revisar cientos de enlaces puede llevar una buena media hora) cuando termine tendrás un hermoso conjunto de unos pocos cientos de enlaces de recursos que funcionan.
Código Completo
# grab the list of all the resources at https://challenges.hackingchinese.com/resources
import requests, time
desde bs4 import BeautifulSoup
# links that hold the correct content, not headers and other HTML
true_links = []
def extract_resources(page: int) -> None:
page = requests.get(f'https://challenges.hackingchinese.com/resources/stories?page={page}')
soup = BeautifulSoup(page.contenido, 'html.parser')
# links are stored within a unique header on each card
links = soup.find_all('h4')
for i en range(len(links)):
try:
if links[i]['class'] == ['card-title']:
true_links.append(links[i])
except:
pass
for i en range(1, 10):
extract_resources(i) # 9 different pages with info
file = open("links.txt", "w+")
for i en range(len(true_links)):
try:
# ensure it is a working link
response = requests.get(str(list(true_links[i].children)[0]['href']), timeout = 5, allow_redirects = True, stream = True)
if response != 404:
file.write(str(list(true_links[i].children)[0]['href']) + '\n')
except: # Connection Refused
pass
file.close()
Conclusión
En esta publicación, hemos aprendido cómo:
- Ver el código fuente de una página
- Raspar un sitio web para datos específicos
- Escribir en archivos con Python
- Comprobar enlaces rotos
Aunque solo tocamos la superficie del tipo de web scraping que se puede hacer en Python con las bibliotecas adecuadas, espero que incluso esta rápida introducción te haya enseñado cómo aprovechar el poder de la programación para raspar sitios web automáticamente. Te animo encarecidamente a consultar la documentación oficial tanto de requests y BeautifulSoup si quieres profundizar más en el mundo del raspado de datos, y ver si hay algún dato que tú puedas recopilar de la web y usar en tus propios proyectos.
¡Házme saber en los comentarios qué estás raspando o si necesitas más ayuda!
¡Feliz Programación!
Deja un comentario